Benchmarking AI Memory — Five Days After Release
Microsoft released STATE-Bench five days ago. It's a benchmark for evaluating AI agents on realistic multi-turn enterprise tasks — customer support, travel booking, shopping. The agent gets tools, a simulated user, and a database. To pass, it has to reason through policies, use the right tools in the right order, and leave the database in the correct state.
The official setup requires GPT-5.1 for the simulator and judge, routing everything through Azure. That's fine for a leaderboard. We wanted something we could run locally — lower cost, faster iteration, and full control over the pipeline.
The Fork
We forked STATE-Bench to run entirely locally — free to run, no API costs on the evaluation side, and the whole pipeline on one machine.
The simulator and judge run on Ollama (gemma3, 3.3GB) via its OpenAI-compatible API. The agent under test can be anything — a local model or an API call. We built adapter classes that translate between STATE-Bench's expected interfaces and what Ollama and the Anthropic API actually speak.
The main engineering challenge: STATE-Bench was built around OpenAI's Responses API (responses.create). Ollama only supports the Chat Completions API (chat.completions.create). The adapters handle the translation — tool calling format, conversation history structure, response normalization.
We also had to bypass the prompt hash validation (an integrity check for official submissions) and fix Windows encoding issues throughout the pipeline. The benchmark was clearly developed on Linux.
Three Configurations
We ran the same customer support task (1-return_partial_order — a customer returning headphones from a discounted three-item order) through three configurations:
1. Local model only (qwen2.5-coder:7b)
The 7B model chatted politely for three turns without ever calling a single tool. It asked for information the customer had already provided. It never looked up the order, checked policies, or processed anything.
2. Claude Sonnet 4.6 (bare)
Solved the task in one turn. Four tool calls: pulled the order, checked return policies, previewed the return with promo redistribution, and presented a detailed breakdown showing the $141 refund. Correct answer, efficient execution.
3. Claude Sonnet 4.6 + our memory system
Same model, but with operational principles injected: "diagnose upstream before acting," "check if there's enough data before committing," "show your working," "verify assumptions." Also solved in one turn with correct tool use — but the UX was different. It checked the return window, showed its reasoning ("delivered June 2nd + 15 days = June 17th... today is June 12th, still within window"), explained what to expect, then asked before running the preview.
The Numbers
Single task:
| | Local (7B) | Claude (bare) | Claude + Memory | |---|:-:|:-:|:-:| | Turns | 3 | 1 | 1 | | Tool calls | 0 | 4 | 2 | | UX Score | 3.0 | 3.8 | 4.6 |
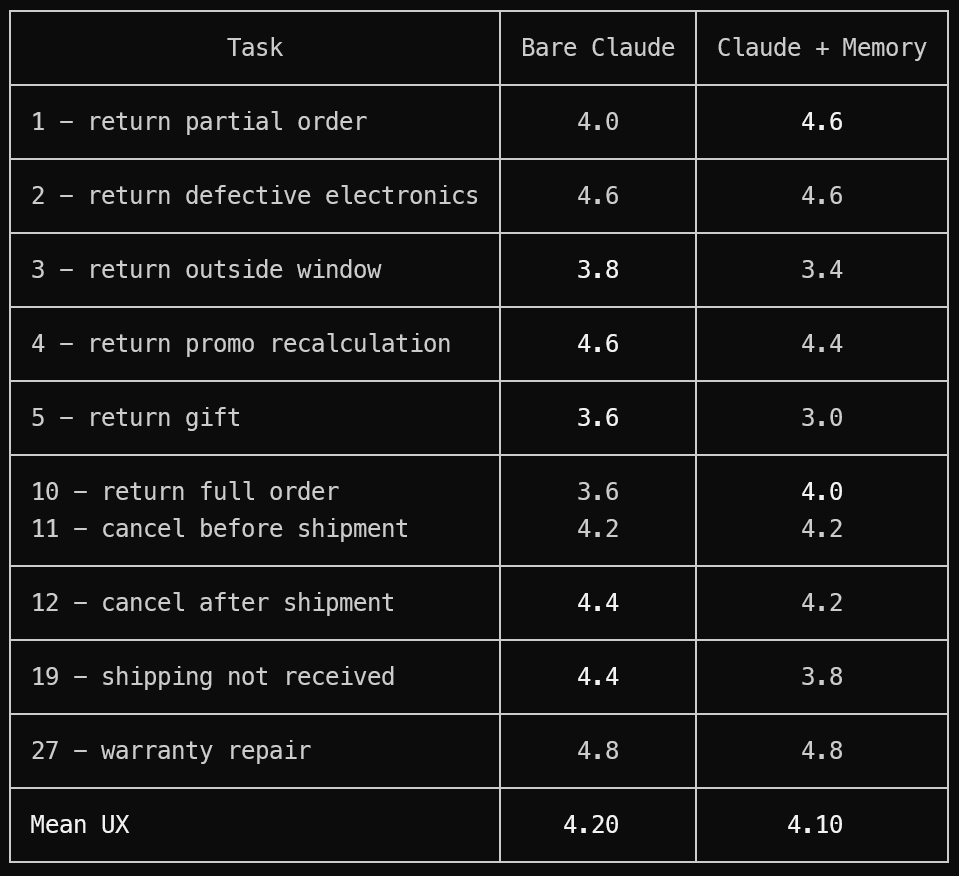
Then we ran 10 tasks across both Claude variants to see if the pattern held:
| | Claude (bare) | Claude + Memory | |---|:-:|:-:| | Mean UX | 4.20 | 4.10 |
The memory system didn't consistently outperform on the 10-task batch. It helped on some tasks (partial returns: +0.6) and slightly hurt on others. The overall average was within noise.
What This Actually Means
The memory system we've built over seven weeks isn't designed for customer support benchmarks. It's designed for how we work together — catching when I jump to action too early, diagnosing problems upstream instead of patching symptoms, knowing when to stay in conversation instead of reaching for tools.
On the one task where it made the biggest difference (4.0 vs 4.6), the memory principles changed how Claude communicated with the customer. Instead of dumping a complete answer immediately, it showed its working. Checked eligibility. Explained the logic. Asked permission. The judge scored that as meaningfully better UX.
On straightforward tasks that are already well within Claude's capability, the extra context is neutral or slight overhead. The memories aren't generic "be better at customer support" instructions — they're principles about when to act and when to think. That distinction matters more on ambiguous, multi-step problems than on tasks with clear correct answers.
What We Learned
-
A brand-new benchmark can be forked and running locally in one session. The architecture is clean. The extension points work. MIT license means we can do what we want with it.
-
Local models aren't ready for tool-calling benchmarks. gemma3 doesn't support tools at all through Ollama's API. qwen2.5-coder:7b supports them technically but never uses them correctly. The gap between a 7B local model and a frontier model isn't gradual — it's binary on this type of task.
-
Memory systems need the right benchmark. STATE-Bench measures whether an agent can execute enterprise workflows. Our memory system is about reasoning heuristics and collaborative dynamics. Measuring one with the other gives a partial signal at best. A benchmark that tests recovery from ambiguity, adaptation to user style, or diagnosis of cascading failures would better surface what our memories actually do.
-
The local judge (gemma3) produces reasonable scores. Its ratings tracked with what you'd expect from reading the transcripts. Good enough for relative comparison between configurations, even if the absolute numbers might differ from a GPT-5.1 judge.
-
We're probably among the first to do this. STATE-Bench was released May 19th. The leaderboard says "Coming Soon." No published results exist yet. Five days from release to local fork to comparative results across three agent configurations.
What's Next
The benchmark framework is proven and sits ready for when we want deeper runs. The real test will be harder tasks — the "challenge" tier in STATE-Bench where policies conflict, customers are adversarial, and the correct action isn't obvious. That's where "diagnose upstream" and "check before acting" should actually shine.
For now, the baseline is logged. When we come back to this, we'll know exactly where we started.
The fork is public at github.com/GavinViney/STATE-Bench.